


Marco Slot
Distributed PostgreSQL has become a hot topic. Several distributed database vendors have added support for the PostgreSQL protocol as a convenient way to gain access to the PostgreSQL ecosystem. Others (like us) have built a distributed database on top of PostgreSQL itself.
For the Citus database team, distributed PostgreSQL is primarily about achieving high performance at scale. The unique thing about Citus, the technology powering Azure Cosmos DB for PostgreSQL, is that it is fully implemented as an open-source extension to PostgreSQL. It also leans entirely on PostgreSQL for storage, indexing, low-level query planning and execution, and various performance features. As such, Citus inherits the performance characteristics of a single PostgreSQL server but applies them at scale.
That all sounds good in theory, but to see whether this holds up in practice, you need benchmark numbers. We therefore asked GigaOM to run performance benchmarks comparing Azure Cosmos DB for PostgreSQL to other distributed implementations. GigaOM compared the transaction performance and price-performance of these popular managed services of distributed PostgreSQL, using the HammerDB benchmark software:
- Azure Cosmos DB for PostgreSQL (with Citus distributed tables)
- CockroachDB Dedicated
- Yugabyte Managed
You can find the full GigaOM benchmark report at: GigaOM: Transaction Processing & Price-Performance Testing.
In this blog post, you’ll see why benchmarking databases is so hard, why the TPC council’s HammerDB is an awesome benchmarking tool, and why Citus is fast.
Why it’s hard to benchmark database performance
Benchmarking databases, especially at large scale, is challenging—and comparative benchmarks are even harder. It starts with the choice of workload and the benchmarking tool. There are many to choose from, but few are well-established, and even fewer are (somewhat) representative of real-world workloads. Once you choose one, there are many parameters to tweak for both the benchmarking tool and the system under the test, and it’s impossible to evaluate all combinations.
Whenever you run a benchmark, you usually learn that you should have run something else instead. For instance, you might realize the benchmark is I/O intensive and your disk configuration was quite modest, or that the response times are too high and the number of connections too low for the benchmark to put meaningful load on the system under test. Once you realize that you need to change a parameter, you may also need to go back and change it for other configurations. Given that running a single benchmark can take hours and you typically do multiple runs, it can keep you busy for a long time.
The hardest part perhaps is knowing why you get certain results or at least gaining high confidence in the results. Running benchmarks is like running software: It’s hard to know the complete state of the system, especially without affecting performance, and bugs can spoil everything.
Because we know how hard it is to run benchmarks, we are always cautious about publishing benchmark numbers—and we set the following rules for ourselves:
- Supply all the benchmark parameters needed to reproduce the numbers
- Use a trusted benchmarking tool for high throughput benchmarks, do not create your own
- Do not copy numbers from other sources to compare against your own
- Be honest about the workload, provide necessary context
- Create a fair playing field (e.g. all managed service, or all on the same hardware)
- Repeat and build high confidence in the results
- Hire a third party to run the benchmarks, if possible
We try to follow these rules whenever we share benchmark numbers, even if it they are not a comparison to other systems.
HammerDB is an open-source benchmarking tool by Steve Shaw for benchmarking relational databases.
A unique thing about HammerDB is that it is managed by the Transaction Performance Council (TPC). Every significant change is voted on by the TPC-OSS committee which includes members from different database vendors. HammerDB implements a transactional and an analytical workload for each of the major relational database management systems (Oracle, SQL Server, MySQL, MariaDB, DB2, and PostgreSQL), and implicitly for any database system that supports one of those protocols. Voting on pull requests helps keep the tool fair to different vendors.
The transactional workload in HammerDB closely follows the TPC-C specification, but simply running HammerDB is not the equivalent of running a compliant TPC-C benchmark. Hence, the transactional workload in HammerDB is labelled “TPROC-C”. The TPC-C specification models an order processing system for an organization with many warehouses. Most transactions are scoped to a single warehouse, similar to multi-tenant workloads. The data size is proportional to the number of warehouses.
The TPROC-C workload can have slightly different characteristics than TPC-C. The original TPC-C specification models an information system with physical terminals on which users enter orders manually. Hence, there are relatively long pauses (“keying time”) between transactions belonging to the same warehouse. That means that the number of transactions per minute per warehouse is ultimately bounded to a low number. In that scenario, the performance at a given scale factor might say little about the achievable performance of the system under test, because the throughput is artificially capped. Instead, TPC-C typically involves finding the scale factor that maximizes performance, which is a more involved process and harder to compare across database systems.
In practice, application servers keep a pool of database connections and generate tens or hundreds of transactions per second per connection. One way to model that in HammerDB TPROC-C is to set the “Repeat Time” to the lowest possible value. That way, we can look directly at the throughput a given system can achieve at a given scale factor, which simplifies comparison.
HammerDB expresses throughput as NOPM (New Orders Per Minute), which reflects the rate of “new order” transactions. On average, new order transactions represent ~43% of the total, so the actual number of transactions per minute is ~2.3x higher. The reason for using the NOPM metric is that this number of new order transactions performed can be accurately counted by inspecting the state of the database. NOPM is based on “tpmC” in the TPC-C specification.
Benchmark results for transaction processing & price-performance
GigaOM used HammerDB TPROC-C to benchmark Azure Cosmos DB for PostgreSQL and two comparable managed service offerings: CockroachDB Dedicated and Yugabyte Managed. However, they found that CockroachDB is not sufficiently compatible with PostgreSQL to support the HammerDB TPROC-C workload. The CockroachDB Dedicated results therefore use the TPC-C-based benchmarking tool that comes with CockroachDB itself, while HammerDB was used for Azure Cosmos DB for PostgreSQL and Yugabyte Managed.
GigaOM initially used 1,000 warehouses for their benchmarks, which results in ~100GB of data. However, both CockroachDB and Yugabyte gave surprisingly low throughput. They could get better performance by increasing the number of warehouses for both, without changing the number of connections. While it is typical for TPC-C performance to be proportional to warehouse count, this is not the case for TPROC-C without keying time. The benchmarking workload was also identical between Yugabyte and Azure Cosmos DB, so it is not a characteristic of the workload.
The full report is available at:
The key results are shown in the chart below:
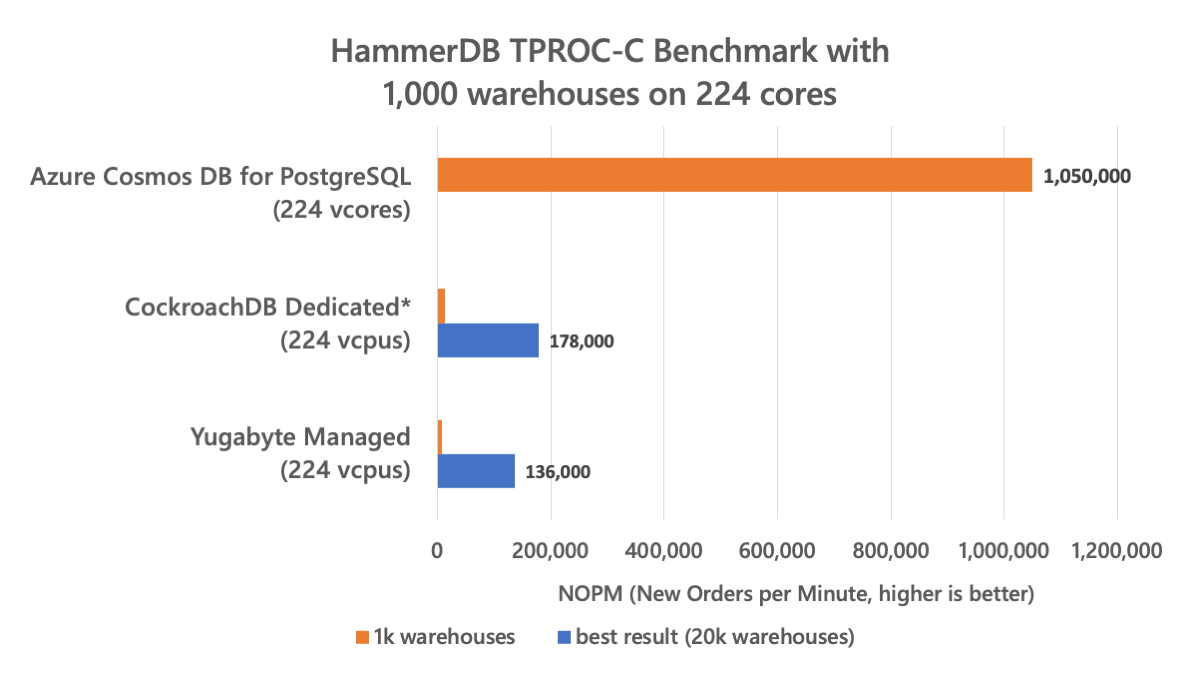
There was not enough time in the project for GigaOM to run HammerDB with 10k and 20k warehouses on Azure Cosmos DB for PostgreSQL, but in our own benchmarks we confirmed it does not substantially change the performance compared to 1k, so performance is not as dependent on data size.
Why Azure Cosmos DB for PostgreSQL is so fast
How can Azure Cosmos DB for PostgreSQL be so fast? As I mentioned at the beginning, the Citus extension that powers Azure Cosmos DB for PostgreSQL is all about high performance at scale (hint: it’s in the name).
An important concept in Citus is co-location. To distribute tables, Citus requires users to specify a distribution column (also known as the shard key), and multiple tables can be distributed along a common column. That way, joins, foreign keys, and other relational operations on that column can be fully pushed down. Moreover, transactions and stored procedures that are scoped to one specific distribution column value, can be fully delegated to one of the nodes of the cluster, which is essential in achieving transactional scalability. Finally, Citus relies fully on PostgreSQL to handle the storage, indexing, and low-level query execution, which has been tweaked and tuned for three decades.
If you do not distribute tables in Azure Cosmos DB for PostgreSQL, you are using regular single node PostgreSQL. So, using Citus necessarily means defining distribution columns. In HammerDB, distributed tables can be enabled by enabling the pg_cituscompat option.
Distributed systems, and distributed databases especially, are all about trade-offs at every level. CockroachDB and Yugabyte make different trade-offs and do not require a distribution column. Engineers like talking about the CAP theorem, though in reality there are many thousands of tricky trade-offs between response time, concurrency, fault-tolerance, functionality, consistency, durability, and other aspects. You should of course decide which characteristics are most important to your application.
The decision to extend Postgres (as Citus did), fork Postgres (as Yugabyte did), or reimplement Postgres (as CockroachDB did) is also a trade-off with major implications on the end user experience, some good, some bad.
You can run the benchmarks yourself!
Want to see the performance for yourself? We previously shared tools to run HammerDB benchmarks on Azure Cosmos DB for PostgreSQL. Jelte Fennema wrote a great blog post on benchmarking that describes how you can run these tools in a fully automated fashion (including cluster set up and tear down on Azure).
We also recommend running benchmarks that match your workload. Your application might not need it yet, but one day getting high performance at scale might be what keeps your business going.
If you want to learn more about how Citus works, I suggest checking out my vaccination database tech talk on Citus at CMU. Or, you can follow everything we do on the Citus GitHub repo.
Azure Cosmos DB is a fully managed NoSQL and relational database for modern app development with SLA-backed speed and availability, automatic and instant scalability, and support for open-source PostgreSQL, MongoDB, and Apache Cassandra. Try Azure Cosmos DB for free here. To stay in the loop on Azure Cosmos DB updates, follow us on Twitter, YouTube, and LinkedIn.
Post Disclaimer
The information provided in our posts or blogs are for educational and informative purposes only. We do not guarantee the accuracy, completeness or suitability of the information. We do not provide financial or investment advice. Readers should always seek professional advice before making any financial or investment decisions based on the information provided in our content. We will not be held responsible for any losses, damages or consequences that may arise from relying on the information provided in our content.

{kind=link}