


The emergence of Large Language Models has revolutionized language processing, offering limitless potential applications. However, these models present substantial technical challenges in their deployment, training, and optimization. By adopting an effective LLMOps strategy, organizations can ensure optimal performance, scalability, and efficiency of their language models. This enables them to fully utilize these models to enhance customer experience, increase revenue growth, and strengthen their competitive advantage. Let’s delve deeper into LLMOps, its best practices, and techniques.
Understanding LLMOps
LLMOps stands for Large Language Model Operations, which entails managing, deploying, and optimizing large language models such as Bloom, OPT, and T5. It is a set of principles and practices designed to bridge the gap between LLM development and deployment. It outlines the automation and monitoring processes throughout the LLM development process, including integration, testing, releasing, deployment, and infrastructure management.
Generative AI solution development is a complex process that involves more than just training an LLM. As shown in the following diagram, model training is just one of many functions that need attention. Each of these elements requires technical expertise, making the development of an LLM solution a highly collaborative effort involving data scientists, software engineers, DevOps engineers, and other stakeholders. The complexity of these systems increases when they are deployed in a production environment, where they must handle high volumes of data, provide real-time predictions, and be highly available and reliable.
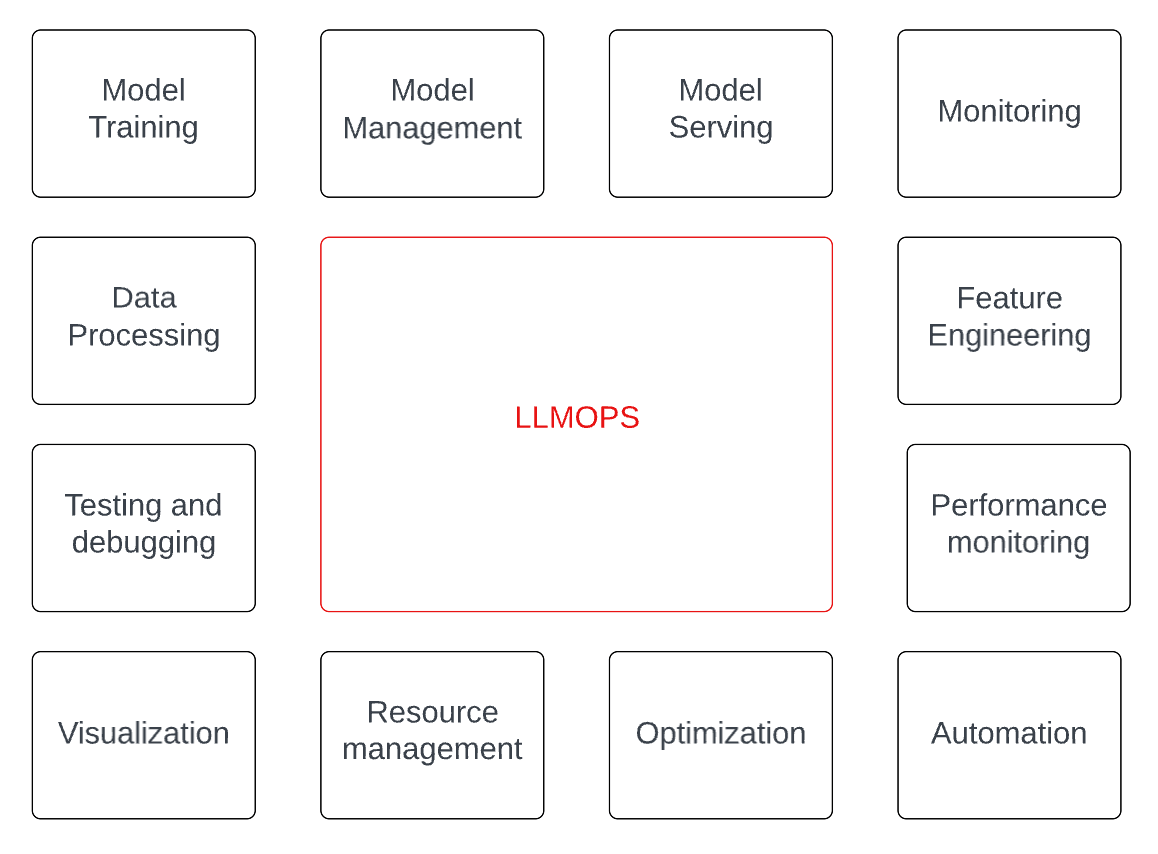
LLMOps is a growing field that concentrates on developing strategies and best practices for managing large language models, including infrastructure setup, performance tuning, data processing, and model training. An effective LLMOps strategy can ensure optimal language model performance, scalability, and efficiency, enabling organizations to unlock their full potential and gain a competitive edge.
The Architecture of LLMOps
Large language models require significant computational resources to process data and generate predictions. The architecture should be designed to efficiently use hardware resources such as GPUs and TPUs. A well-designed LLMops can effectively handle large volumes of data and support real-time applications by optimizing for low latency and high throughput.
A robust and automated CI/CD (Continuous Integration/Continuous Deployment) system is required to ensure that pipelines in production are updated quickly and reliably. This system enables data scientists to rapidly experiment with new concepts related to feature engineering, model architecture, and hyperparameters. By implementing these ideas, the scientists can automatically build, test, and deploy the new pipeline components to the target environment.
The diagram below illustrates the implementation of an LLM pipeline using CI/CD. The pipeline consists of several components: data preparation, feature engineering, model training, and deployment. The automated CI/CD system is integrated into this pipeline to facilitate each component’s automatic building, testing, and deployment.
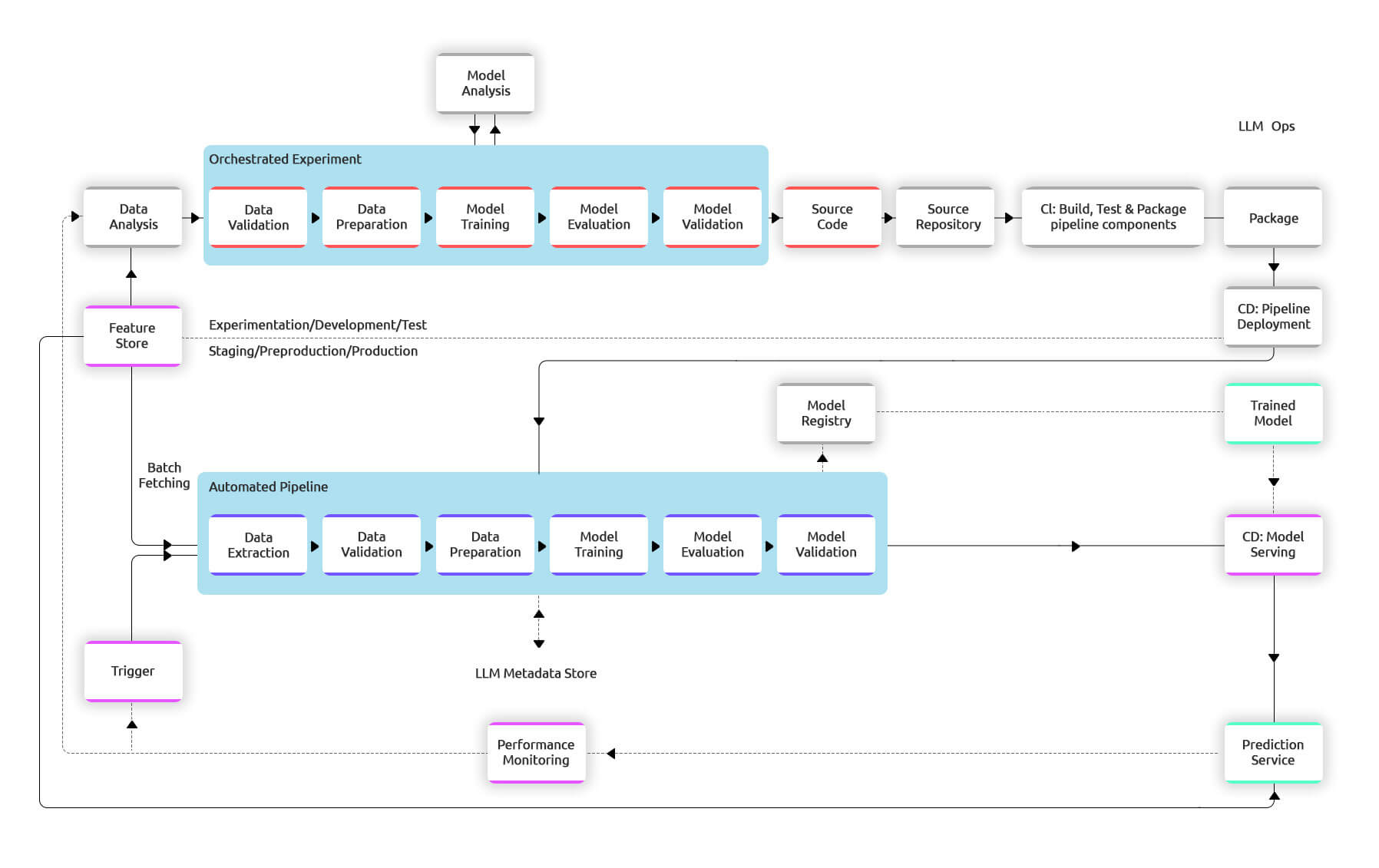
The pipeline comprises various stages to ensure a smooth training and deployment process. Initially, development and experimentation involve iterative testing of LLM algorithms and modeling, with the output being the source code for the GAI pipeline steps. Next, continuous integration involves building and testing source code, with the outputs being pipeline components for deployment. In the continuous delivery stage, artifacts from the previous stage are deployed to the target environment, resulting in a deployed pipeline with the new model implementation. The pipeline is then automatically triggered in production based on a schedule or trigger, leading
Post Disclaimer
The information provided in our posts or blogs are for educational and informative purposes only. We do not guarantee the accuracy, completeness or suitability of the information. We do not provide financial or investment advice. Readers should always seek professional advice before making any financial or investment decisions based on the information provided in our content. We will not be held responsible for any losses, damages or consequences that may arise from relying on the information provided in our content.

{kind=link}